Elnur Hajiyev, Nigar Huseynova, Aysu Tinayeva, Rovshan Khalilov, Mahammad Nadirov
DOI: https://doi.org/10.30546/300045.2026.03.1.509
Abstract
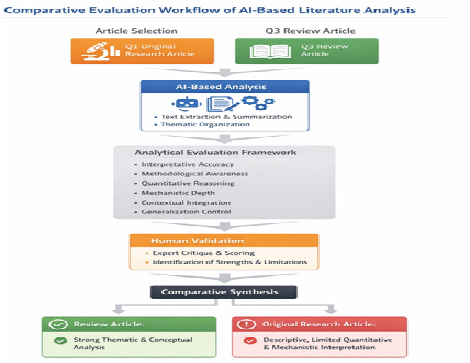
Artificial intelligence (AI)-based tools are increasingly used in academia to support literature reviews, preliminary research exploration, and manuscript screening. However, their ability to perform higher-order scientific reasoning and critically evaluate research remains unclear. This study critically assessed an AI program’s analytical performance across two biomedical article types: a Q1 original research article and a Q3 review article. Using a qualitative, comparative case-study design, AI-generated analyses were evaluated by human experts based on interpretative accuracy, methodological awareness, quantitative reasoning, mechanistic depth, and contextual integration. The AI performed well on the review article, demonstrating strong thematic organization, conceptual summarization, and identification of broad research gaps. In contrast, its analysis of the original research article was largely descriptive, with limited engagement in quantitative data interpretation, mechanistic insight, and methodological critique, and included overgeneralizations of biological conclusions. These findings indicate that while AI tools can support literature exploration and education, they are not yet suitable as independent evaluators of high-impact research. Future development should focus on quantitative reasoning, mechanistic interpretation, and article-type–aware strategies to enhance scientific rigor.